Above is an illustration of an end-to-end analytical workflow. I've been putting a bunch of puzzle pieces together in VerbaGPT to be able to run such a workflow autonomously. I was finally able to test it.
For my example, I wanted to use 2023-2024 Affordable Care Act (ACA) Minimum Loss Ratio (MLR) data to extract interesting insights and patterns. This is not a simple dataset. It is a set of a dozen different files for each year where you need to do complicated joins between them to answer questions, and the amount values in columns depend on what is in the row for a description column, different quantities are similarly named, lots of industry jargon, data is self-reported and messy, etc. Like I said, not simple.
I asked VerbaGPT in local mode to:
- download 2023-2024 MLR data from CMS website,
- understand documentation, extract and organize the files in my local folder
- securely load it into a snowflake database I had set up previously
- inspect loaded data, identify and remove unreasonable data
- analyze the data to answer my complex question
- and finally, do a deep review of all the code and narrative
And I asked it to do all of this in one go (took about 20 minutes). That's a lot of instruction and a lot of steps - but in VerbaGPT it's wrapped in a reusable "project." Once created, steps are trivial to add to or edit, and future runs inherit all that context automatically. The big idea here is that for any repeatable and complex analysis or deliverables, we can set up a workflow that can produce a high quality output reliably. Due to the probabilistic nature of LLM generations, you don't get the same output twice. This is a feature and can be a bug. The right LLM harness increases the odds of the former.
I want to reinforce the point around context. Crucially, LLM results deteriorate when too much context is added, or it is asked to do a lot at once. This is just like giving a person a 20-point instruction, if they are like me, they'd forget 30% of it instantly. Which is a key reason why the project framework in VerbaGPT is critical. Steps run sequentially without biting off more context than the LLM can chew, and building on the prior steps - with the option of having user manual review or AI autonomous review after each step for accuracy and reasonableness. You know, like a regular data analysis workflow with a team of people. Except, its autonomous.
Of course, things aren't as simple and work needs to be done especially at the start to identify and subsequently avoid the pitfalls. I needed to give it an analysis "skill" (which is relatively simple notes that are progressively loaded by the LLM at run time) so that it defines profitability the way I wanted it to, and also avoid a data issue or two that it tripped over on the first go. An example of a data issue: it summed up rows including "grand total" rows, effectively doubling member months. And once set up properly, it doesn't make the same mistake again.
Surprisingly, I didn't have to fix anything for data ETL - it encountered hiccups, but recovered automatically and correctly loaded the data into snowflake.
I don't want to give the impression that LLMs are magic. They aren't. But with the right tooling, early results show us a window to an amazing opportunity.
Results
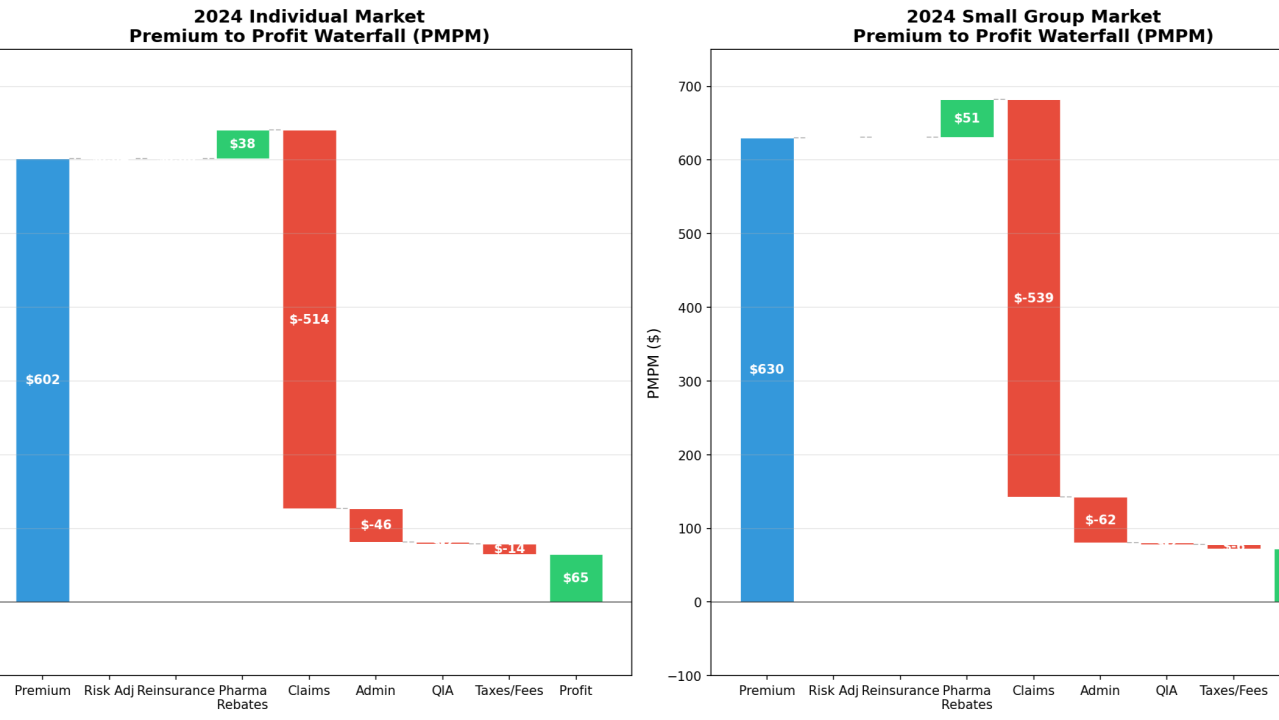
Speaking of results, here is a sampling of the visuals and insights produced by the analysis. Here is the question that I asked.
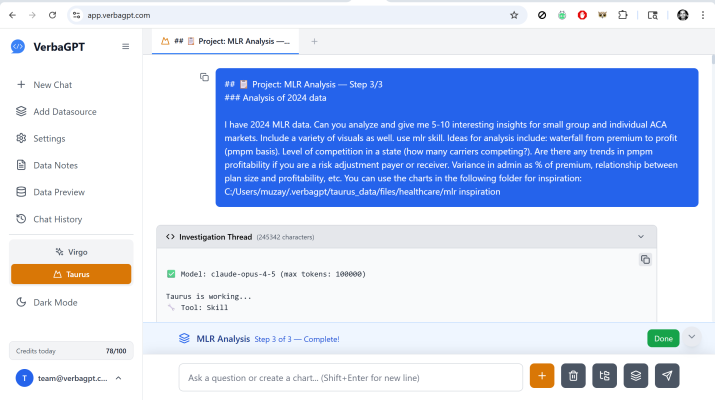
In case the image above is blurry, the question was:
Project: MLR Analysis — Step 3/3
Analysis of 2024 data
I have 2024 MLR data. Can you analyze and give me 5-10 interesting insights for small group and individual ACA markets. Include a variety of visuals as well. use mlr skill. Ideas for analysis include: waterfall from premium to profit (pmpm basis). Level of competition in a state (how many carriers competing?). Are there any trends in pmpm profitability if you are a risk adjustment payer or receiver. Variance in admin as % of premium, relationship between plan size and profitability, etc. You can use the charts in the following folder for inspiration: C:/Users/muzay/.verbagpt/taurus_data/files/healthcare/mlr inspiration
Here are a few of the visuals and findings.
Chart 1: Risk adjustment transfer receivers are more likely to be profitable. Particularly interesting insight as risk adjustment methodologies typically undercompensate riskier members. This has more to do with scale, expertise with documenting diagnoses, and a host of other factors.
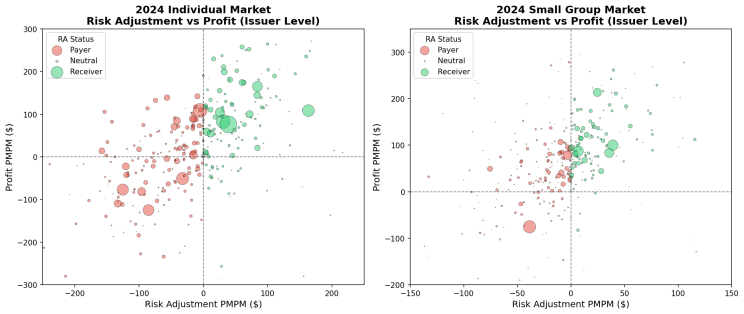
Chart 2: Relationship of size to profitability. We see a bit more of this dynamic in the individual market.
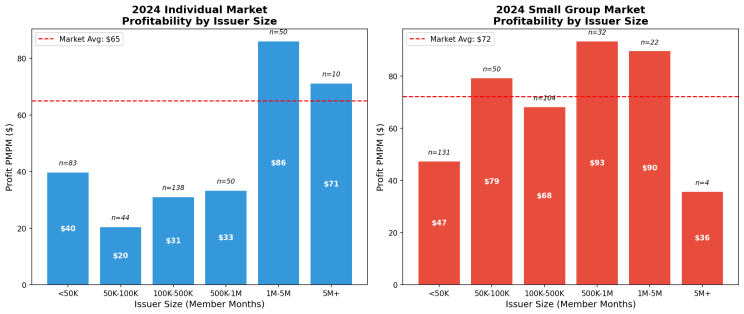
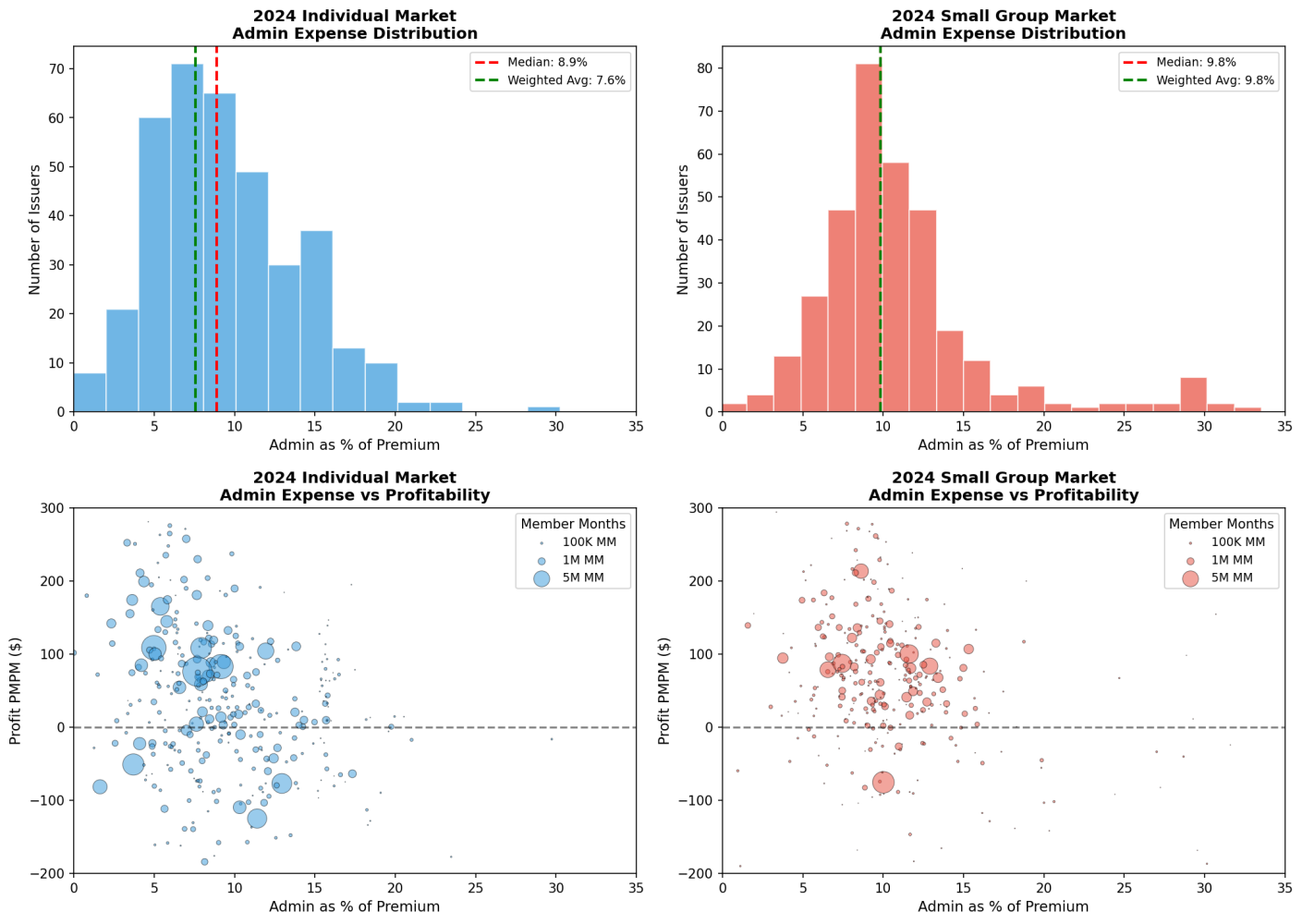
Chart 3: Dispersion of admin costs and relationship to profitability. More variation in individual.
Finally (and this was not part of my project) - I asked it to produce a professional industry article discussing the findings and charts etc. Just as a test. And...it was not good. Needs a lot more work. And that's kind of the fun part. In VerbaGPT I can craft a reusable writing skill and a project that can follow my branding, guidelines, etc. - along with autonomous review parameters before a human spends time reviewing. Will that work? Don't know yet. I'll make a future post along this line of experimentation.
Last word
We have to remember that projects are not just about producing deliverables. The way you get to a good quality deliverable is people with deep domain expertise working on it and collaborating. It is crucial to have an easy way to share prompts and projects that can be iterated on and run by different people in an organization, as well as auditable workflows that can be checked and verified. This is a core philosophy that guides what I build.
But why do we need people running projects, producing deliverables and collaborating if everything can be autonomous?
As I've written before, I don't think we are in a timeline where LLMs will replace knowledge workers, despite the "end-to-end autonomous" capability in a tool like VerbaGPT. The reason is simple. We need professionals wielding these tools. And companies that successfully use AI will need more of them.
I'm not going to replace my accountant with AI. Can I create a tax return? Sure (I actually did with VerbaGPT as a test), but I don't know how to review a finished return for reasonability, to quickly check for accuracy and quality - I don't have the required expertise. However, an accountant could dramatically improve their productivity by using tools like these, and instead of serving x clients, could serve 10x. Same goes for actuaries, lawyers, management consultants, and so on.
I think workers and companies that can harness AI with the right tooling will be in greater demand than ever - a classic case of Jevons' paradox. They will have far greater optionality and capacity to increase earnings and market share. The flip side: organizations that shun these tools, or hobble them with hamstrung implementations, risk falling behind — often by wielding legitimate concerns like security and reviewability as a cudgel against innovation.
Originally posted on LinkedIn on January 13, 2026.