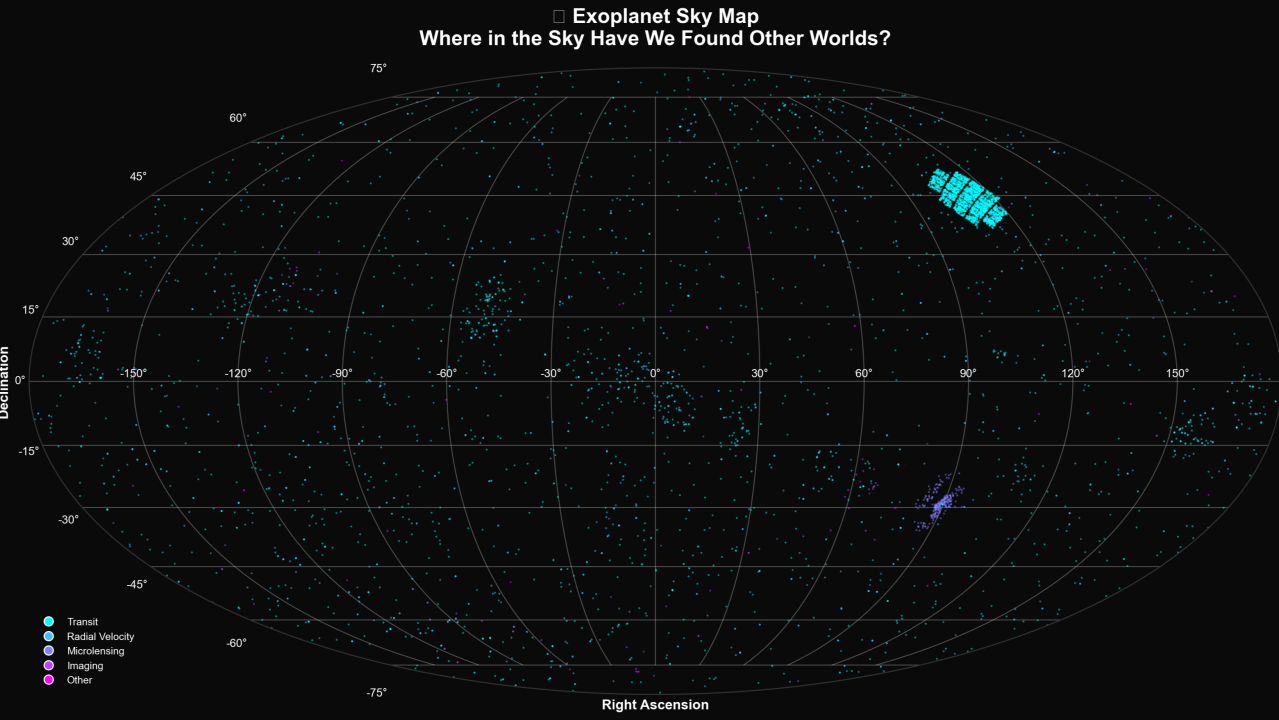
6,000+ worlds discovered — and we've barely looked at most of the sky.
I've written before that using LLMs with numeric data—like databases—can actually reduce hallucinations. LLMs aren't great with numbers or freelancing with facts, but they are very good at writing code. When you lean into that strength, the results can be impressive.
That said, it is important to understand that nothing eliminates the so-called hallucinations or provides some sort of 100% guarantee of correctness. Neither does HI (human intelligence) by the way, but that is a fertile tangent that I'll explore another day.
A Real Example: Exoplanet Analysis
An example is better than exposition. I've always been interested in space and astrophysics. I found a database of the more than 6,000 exoplanets discovered as of December 2025, and analyzed it using VerbaGPT. The results were absolutely fascinating. Even as somebody who wrote a thesis in college on this very topic, I learned so many new things.
But were the insights correct?
On the surface, it appeared that they were. But then you look closer. While the results computed from code were solid, the LLM sometimes adds commentary that is not coming from the data itself. For example, in one test run, it correctly noted that the largest orbital period for an exoplanet is 1.1 million years. Then it added: "this means that the planet could have gone around its parent star 4,000 times since the dinosaurs!".
Fans of Jurassic Park will recall that the correct number is 60 times (≈66 million years since dinosaurs roamed the planet). A hallucination in the commentary layer, even though the underlying analysis was correct.
The Hallucination Problem
So how do we completely eliminate hallucinations in general-purpose frontier AI usage? Nobody has figured that out yet, and they are feeding you marketing snake-oil if they say they have.
We have gone from "this is a problem" to acceptance and rebranding as: "this is a feature, not a bug". There is some truth in that—being non-deterministic, creativity in language and making unexpected associations is what makes the technology so interesting in the first place. But we need to be able to do better when it comes to enterprise analytics.
Implementing Guardrails
I have been implementing several guardrails and best practices to mitigate hallucinations. This includes approaches such as:
- Retrieval Augmented Generation (RAG)
- Context engineering
- Tool use
- Deep Review mode (the latest addition)
What is Deep Review Mode?
The review essentially spools up a new LLM with fresh context that checks in detail, almost reproducing the work of the first LLM instance. It typically takes as much compute to do the review as it does to produce the analysis itself. It's surprising how often it catches things that I didn't catch on my first reading of the results. It caught the dinosaur flub too.
I ran the analysis again, this time it didn't make a prehistoric error. But the analysis is 43 pages long of non-trivial analytics—not including the code it executed. I ran the review, and in the output it did catch something that I had missed.

AI Checking AI (But Not the Answer)
Is an AI checking another AI the answer? No, but it is definitely a big improvement—especially when used in conjunction with other refinements. This can be an important step before the very important step: that of human review.
The key insight is this: use LLMs for what they're good at (writing code, making complex associations) and add layers of verification around what they're not good at (numeric accuracy, factual consistency). A multi-layered approach—code validation, AI review, and human verification—gets us much closer to accuracy than any single layer alone.
Originally posted on LinkedIn on December 21, 2025.